Reference
SSD: Liu W, Anguelov D, Erhan D, Szegedy C, Reed S, Fu CY, Berg AC. SSD: Single shot multibox detector. InEuropean Conference on Computer Vision 2016 Oct 8 (pp. 21-37). Springer International Publishing.Link
DSSD: Fu CY, Liu W, Ranga A, Tyagi A, Berg AC. DSSD: Deconvolutional Single Shot Detector. arXiv preprint arXiv:1701.06659. 2017 Jan 23. Link
TDM: Shrivastava A, Sukthankar R, Malik J, Gupta A. Beyond Skip Connections: Top-Down Modulation for Object Detection. arXiv preprint arXiv:1612.06851. 2016 Dec 20.Link
Summary
SSD and DSSD share lots of common ideas with YOLO and YOLOv2. TDM is an extension of Faster R-CNN. The key motivation of all these three frameworks is that using high resolution features can help improve the detection accuracy, especially for small objects.
Main ideas
SSD
The key difference between SSD and YOLO is illustrated in the picture below.
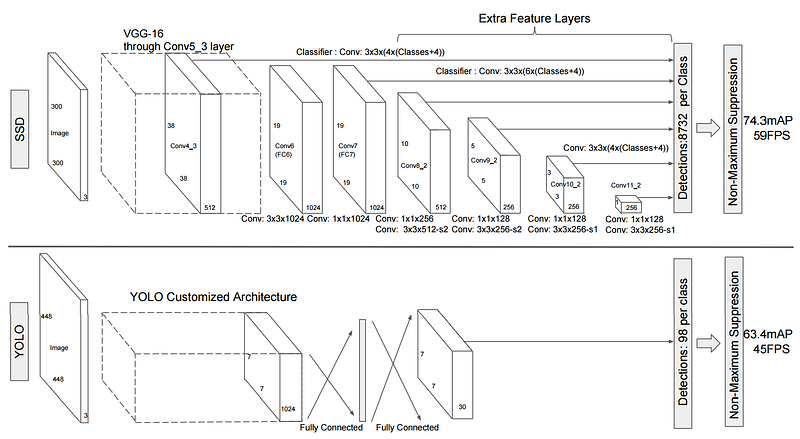
After passing through the base network (e.g., SSD uses the convolution parts of VGG-16), YOLO applies two fc-layers to predict objectness scores and box regresion. On the other hand, SSD adds several convolutions (some layers have stride bigger than one) to create features at different scales and use convolutional layers to generate prediction (using specially designed filter size). Each added convolutional layer is only responsible for predicting objects of a particular scale. After fixing the box aspect ratios, the same set of boxes are applied at different convolutional features. Due to the features are of different scales, the actual predictions are of different scales and aspect ratios.
DSSD
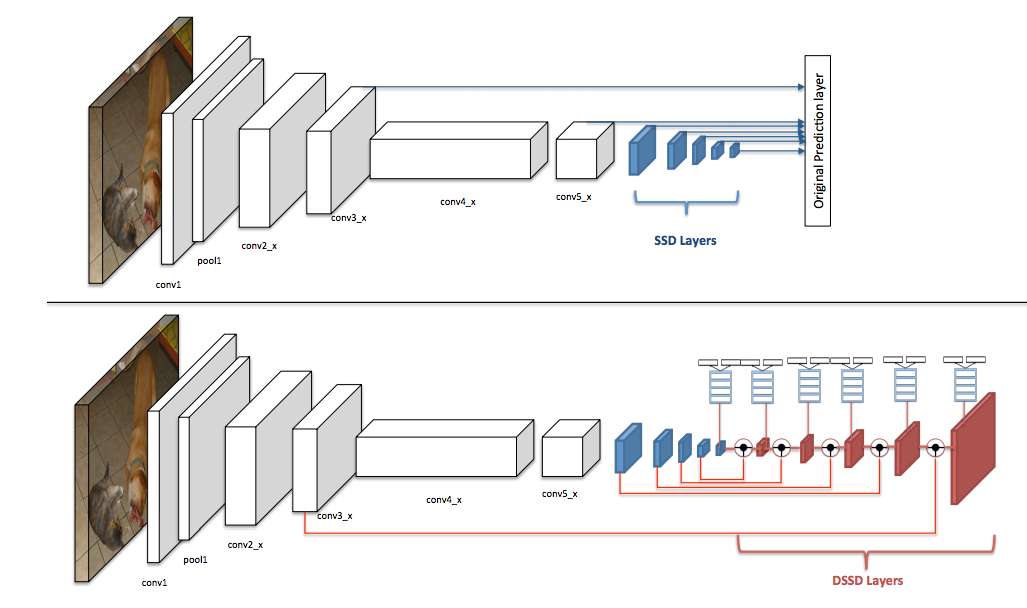
DSSD is improved from SSD. First, ResNet is used instead of VGG. Second, extra convolutional (in form of residual blocks) are added in both the prediction and box regression branches to increase sub-network capacity. Finally, the key improvement is the deconvolution modules (illustrated below). Instead of directly using the features from the added convolutional layers, a sequece of deconvolutional layers are attached after SSD in order to include more high-level context when making prediction based on low-level information. Now, the prediction from features of higher solution not only based on early convolutional layers, but also high-level contexts.
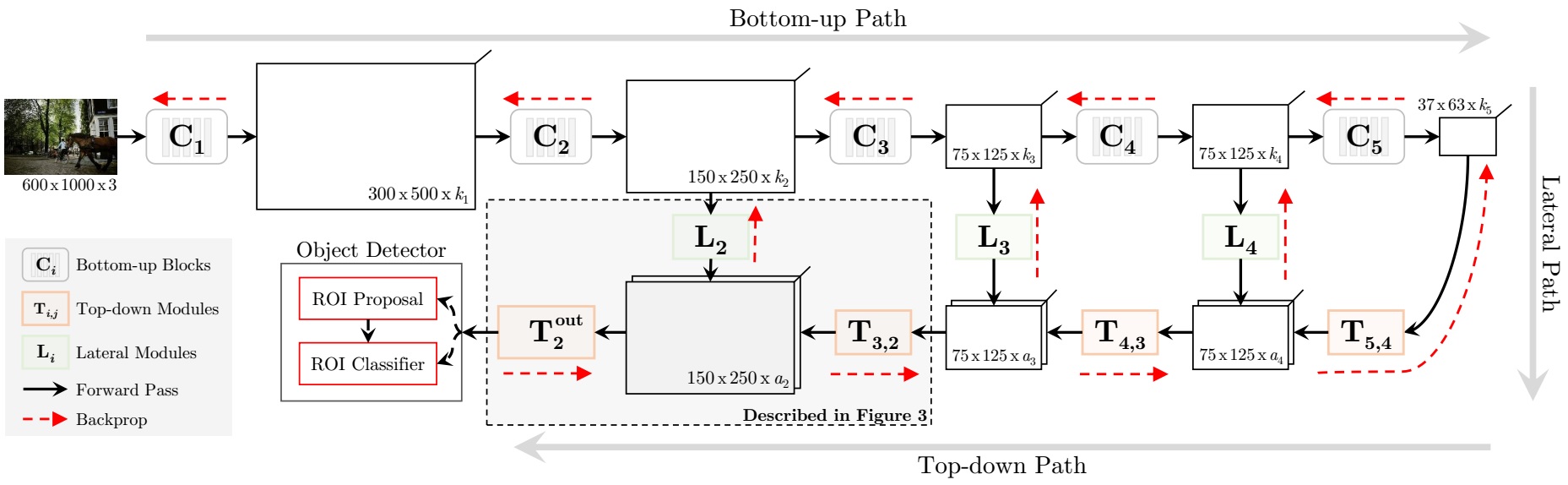
TDM
One step further from DSSD, TDM adds multiple deconvolution layers to gradually restore the features to much higher resolution (see the picture below, which is very similar to U-Net). Only the features from the final layer (high resolution) will be used for detection. Different from the single shot fashion, like YOLO, SSD, DSSD, TDM acts like the extension the RPN in Faster R-CNN. As a resule, evaluating all anchors at the high resolution feature map will incur terribly large computation cost. So, it is applied at a stride so that the computation remains exactly the same as RPN operations in Faster R-CNN.